Originally posted on the Grove blog.
The model gets the headlines. The harness does the work.
Walk into any team that’s shipped an LLM feature to production and you’ll find the same shape underneath: a tool loop with retry and round caps, a streaming layer that has to switch providers when one stalls, sessions that summarize on overflow, a thing that turns external APIs into model-callable tools, a queue or scheduler that fires the same workflow on a cron, an audit log nobody enjoys writing, a disposal endpoint legal asked for last quarter. None of it is the model. All of it is the harness around the model — the runtime that makes a probabilistic next-token machine into a product.
The interesting trend of 2026 is that teams have stopped pretending the harness is a weekend project. The harness is the product. The model is a dependency.
What’s actually in a harness
Every team building agentic software ends up with most of these:
- Tool loop — call model, model asks for tool, run tool, feed result back, model decides to call another tool or finish. Plus a round cap, a policy when the cap hits, and event hooks for narration / progress.
- Provider abstraction with failover — one provider stalls; you swap to another during the stream, not as a retry from scratch.
- Sessions and memory — multi-turn context, rolling summarization, a key-value store the model can read and write to.
- Tool surface — built-in tools (search, time, file ops), customer-supplied tools (your DB, your APIs), tools that live in another process (MCP), tools defined declaratively (OpenAPI-ish specs).
- Auth for the long tail of integrations — OAuth flows, token refresh, per-user / per-customer subjects, scope checks.
- Loop primitives beyond linear — generator/critic, conditional branching, fan-out parallelism, early-response with background work.
- Durable execution — runs survive a process restart; in-flight runs reconcile on boot; nothing shows phantom in-progress state.
- Schedulers — cron triggers, dispatches, HA-safe row claims, dead-letter for permanent errors.
- Streaming all the way out — token-by-token to the caller, plus structured events for tool calls, conditional branches, refine iterations, response-ready, failover.
- Audit, compliance, disposal — what ran, what data flowed where, with proof that disposal happened on demand.
- Operator UI — someone has to look at production. A DAG visualizer, a run inspector, a way to fire a trigger by hand.
- Interop with other harnesses — MCP, in both directions: your harness can call other harnesses’ tools, and your harness can be called as a tool from theirs.
That’s not a feature list — that’s an operating system. Most teams build a fraction of it, ship, and then spend the next eighteen months building the rest while their actual product waits in line.
Why “harness as a service”
The pattern is familiar. Postgres exists so you don’t write a B-tree. Stripe exists so you don’t write a card processor. Auth0 exists so you don’t write OAuth. Each is a hard, broad, slow-moving runtime that one team can do well so the other ten thousand teams don’t have to.
The harness is on the same trajectory. The shape is stable enough now to commoditize. The provider matrix is going to keep churning, the tool ecosystem is going to keep growing, the compliance surface is going to keep expanding — but those are exactly the kinds of churn you want absorbed by infrastructure, not by your product team.
Harness-as-a-service means: you describe the workflow, the harness runs it. You don’t operate the tool loop. You don’t write the failover. You don’t roll your own audit log. You call an API, get a stream of events, and ship.
What Grove ships
Grove is a harness, exposed as a service. Layer by layer:
| Layer | Grove primitive |
|---|---|
| Tool loop | LlmCall with max_tool_rounds + on_tool_rounds_exhausted policy |
| Provider abstraction | Broker over Anthropic, OpenAI, Gemini, Vertex, Azure |
| Streaming + failover | Native token streaming with pre-stream failover — provider swaps before any token reaches the caller |
| Sessions + memory | Sessions with rolling summarization; hierarchical key-value memory with text / image / namespace entries |
| Tools | Built-in (search, memory) · external (your callback) · MCP (proxied) · Connectors (declarative OAuth + HTTP, surfaced as both LLM tools and deterministic connector_call nodes) |
| Loop primitives | RefineNode (generator/critic) · ConditionalNode (branch on predicate) · respond_here (early response, background work continues) |
| Durable execution | Postgres-backed runs · stale-run reconciliation on boot · resume from tool-paused state |
| Scheduler | Cron triggers + dispatches with HA-safe FOR UPDATE SKIP LOCKED claims, retries, dead-letter |
| Structured events | SSE stream: node_started, node_completed, tool_call_requested, backend_failover, narration_emitted, response_ready, refine_iteration_*, conditional_branch_taken |
| Compliance | Per-workflow metadata + audit log · compliance document export · tombstoning + forever-retained disposal_log |
| Operator UI | Arborist — embedded React Flow DAG visualizer with live SSE overlay |
| Interop | MCP server (your workflows callable from Claude Desktop / Cursor) · MCP client (their tools callable from your workflows) |
That’s not “primitives we plan to build.” That’s the surface today, callable from one HTTP API, deployable as one binary on one port.
The interop point
Most harness conversations stop at “we built a runtime.” Grove goes one step further: the runtime is bidirectional through MCP.
Mark a workflow mcp_exposed: true and it becomes a tool any MCP-aware client can call — Claude Desktop, Cursor, an agent in someone else’s harness. Per-key capability scopes restrict what can be invoked; every call lands in the MCP audit log. The same workflow your application runs is the workflow another model can invoke as a tool.
Run the inverse and your workflow can call any MCP server’s tools. Register the server, Grove discovers its tools, the LLM calls them like any other. Plus declarative connectors — point a YAML spec at GitLab, Google Workspace, Gmail, Drive — and the operations show up as both LLM tools (gitlab__create_issue) and deterministic nodes (connector_call: { connector: gitlab, operation: create_issue }).
That’s the harness-as-a-service version of the network effect: the more harnesses speak the same protocol, the less anyone has to build.
What it looks like, in one workflow
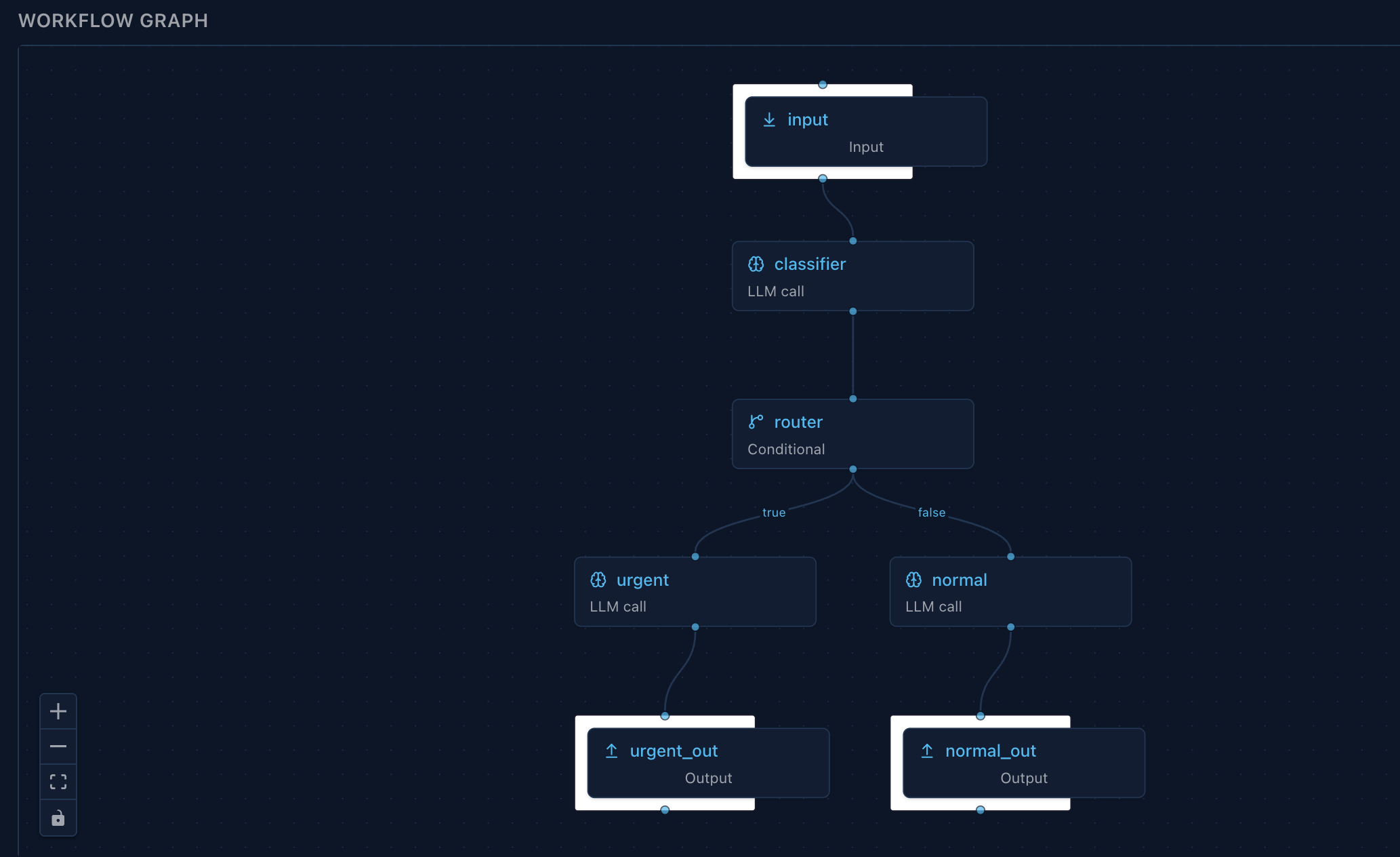
Conditional routing visualized in Arborist — the operator UI Grove ships embedded. Same DAG you wrote in code; live SSE overlay paints node status during a run.
A support assistant: take a customer question, reply fast, classify it, file a GitLab issue if it’s a bug, run every 6 AM against the last day’s digest. One workflow, one run id, one event stream — and the harness layers it exercises:
- Broker resolves
model: "fast"to whichever provider is up; if the chosen provider stalls, the broker fails over before the first token reaches the caller. - Tool loop runs with
max_tool_rounds: 4and an expliciton_tool_rounds_exhaustedpolicy so a runaway agent doesn’t run forever. respond_hereon the reply node emits aresponse_readySSE event the moment the reply is ready — the user sees the answer while the rest of the DAG is still running.- Conditional node routes on
{{nodes.tagger.intent}} == 'bug'. - Connector call on the
bugbranch invokesgitlab.create_issueagainst an OAuth-bound subject — no manual token plumbing in your application code. on_failure: continueon the connector call means a flaky GitLab API doesn’t fail the run; the response was already emitted, the failure lands in the audit log, the run terminates ascompleted_with_non_critical_errors.- Trigger with cron
0 6 * * *runs the digest variant every morning, claimed viaFOR UPDATE SKIP LOCKEDso two scheduler replicas can’t fire it twice. - Audit captures all of it: the workflow definition (immutable), the per-node executions (started, completed, failed, skipped), the response payload, the dispatch row tying the cron fire back to its run.
Eight harness layers, written as one DAG, none of which you operate.
What this gets you back
Engineering hours, mostly. The harness is hard work that doesn’t differentiate your product — every team that builds it builds approximately the same thing. Pushing it down a layer recovers the time you’d spend on it for the work that does differentiate: the prompts, the data model, the UX, the part of the product your customer actually pays for.
It also gets you a contract with the future. The harness layer is where the next year of churn lands — new providers, new tool protocols, new compliance regimes, new agentic patterns. A harness-as-a-service absorbs that churn behind a stable API. Your workflow definitions don’t change when a provider deprecates a model; a model group repoints. They don’t change when a connector spec moves from OAuth 1 to 2; the registry handles it. They don’t change when MCP evolves; the server tracks the spec.
The model is the part everyone notices. The harness is the part that ships.